Differentiable Neural Computer
- 2 minsMuch as a feedforward neural network is to disentangle the spatial features of an input such as an image by approximating some functions, a recurrent neural network (RNN) aims to learn disentangled representations of the temporal features through feedback connections and parameter sharing over time. The vanilla RNN has a caveat of the vanishing gradient problem, and gated RNNs appear as an alternative but the most effective sequence models. The main idea is to create paths in time to prevent back propagated errors from vanishing or exploding. A special variant, called long short-term memory (LSTM) network has been found to be useful in many tasks such as machine translation, voice recognition, and image captioning.
Despite the popularity, RNNs lack the the ability to represent variables and data structures, and to store data over long timescales for solving more complex tasks including reasoning and inference problems. To hurdle the limitations, Graves et al. [1] introduces a differentiable neural computer (DNC), which is an extension of RNNs with an external memory bank that the network can read from and write to. It is broadly considered as augmented RNNs with attention mechanisms [2] that would probably accelerate the power of learning machines.
In this post, I will focus on presenting detailed model schematics without making all intelligible because I have yet to find one such thing that visualizes the whole circuit, and there are already many instructive blogs outlining the key ingredients of the model framework. I personally use it as a cheat sheet for neural network models.
The earlier form of DNC is the neural Turing machine (NTM) [3] developed by the same authors, and they share a large part of the architecture. An elementary module of NTM/DNC is LSTM, referred as to a controller because it determines the values of interface parameters that control the memory interactions. Unfolding the recurrent computation, here is the vanilla LSTM:
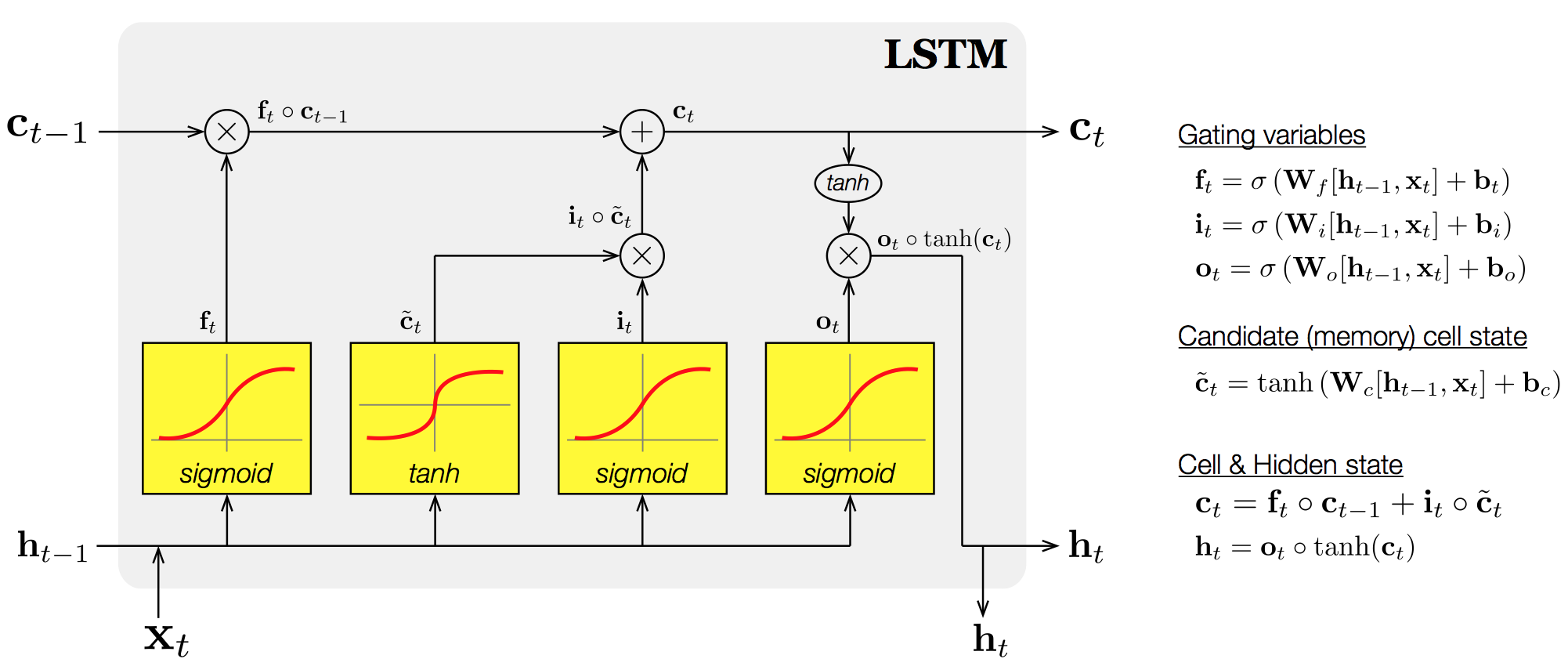
Note that the yellow box represents the set of (input/recurrent) weights to be learned for successfully performing a task given a time-varying input \(\mathbf{x}_t\). Likewise, the controller of NTM is modelled by LSTM with additional sets of weights that determine interface parameters, whereby read-write access to a memory is regulated:
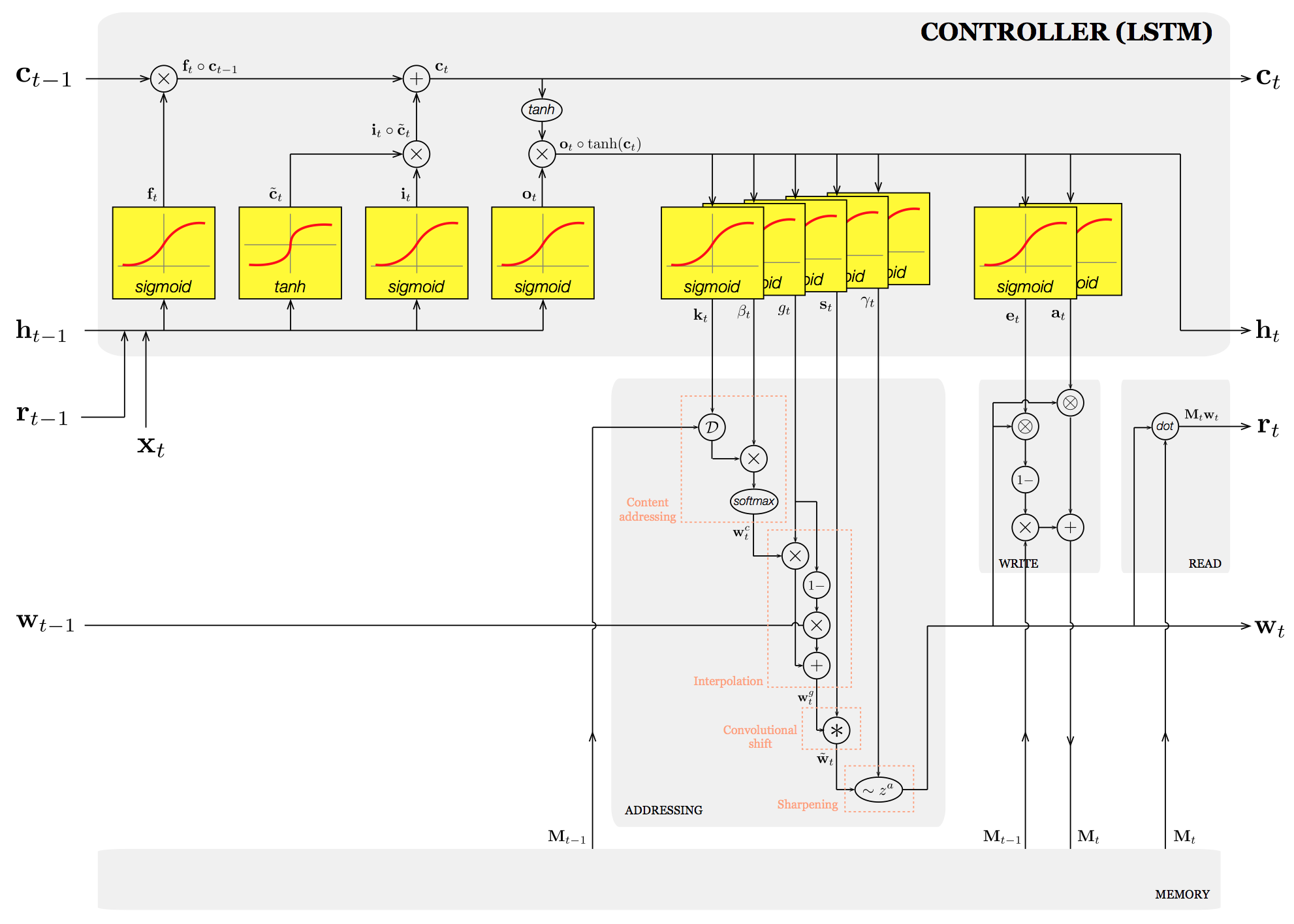
The first architectural difference of DNC from NTM is that DNC employs multiple read vectors and a deep LSTM although they are not necessary conditions. The qualitative difference is that DNC uses the dynamic memory allocation to ensure that blocks of allocated memory do not overlap and interfere. The new addressing mechanism allows to reuse memory when processing long sequences as opposed to NTM.
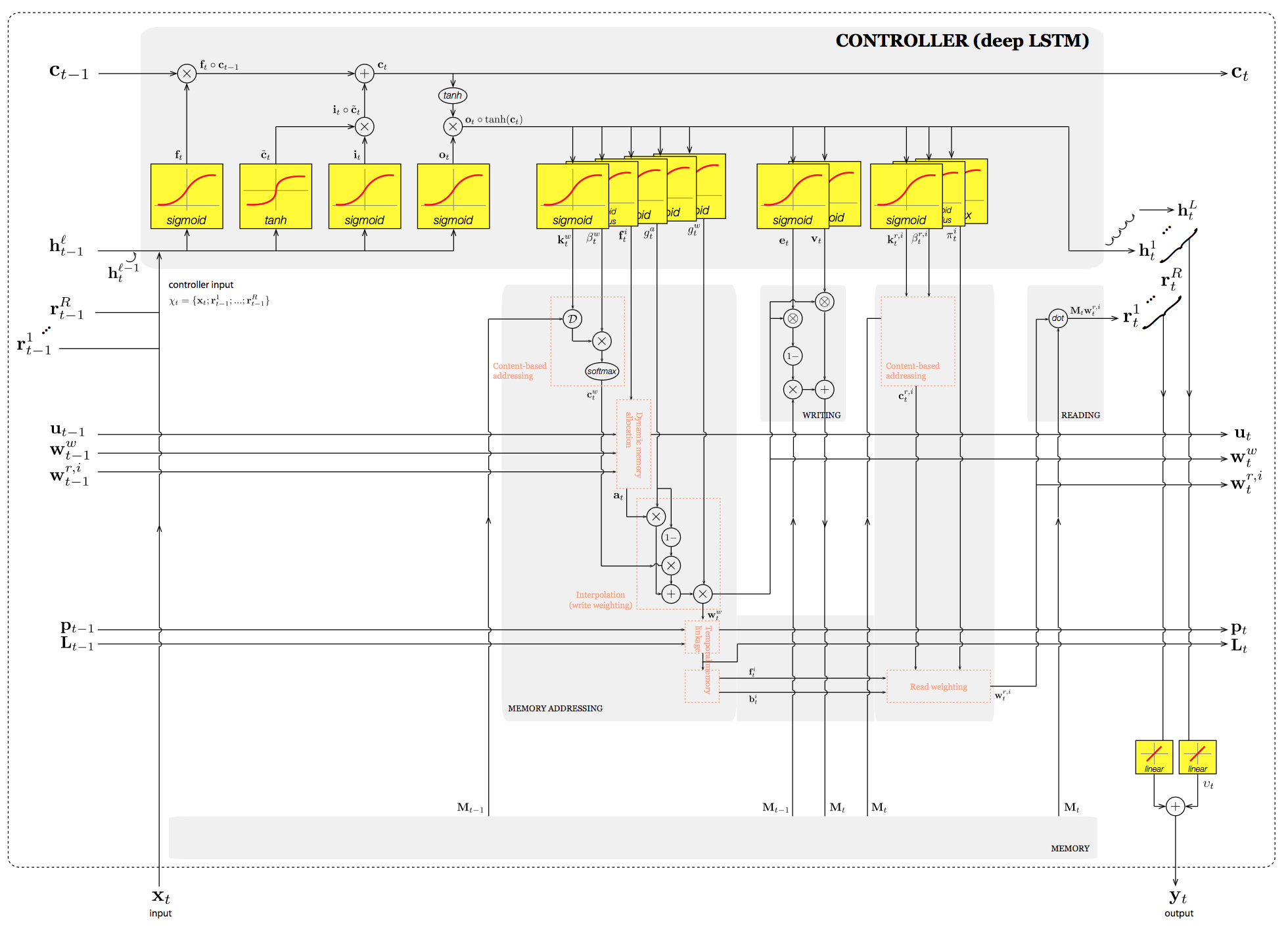
Note that there are some notational mismatches between NTM and DNC, but they are consistent with the original papers.
(still working…)
[1] A. Graves, G. Wayne et al.
Hybrid computing using a eural network with dynamic external memory.
Nature, 2016
[2] C. Olah and S. Carter
Attention and Augmented Recurrent Neural Networks
Distill, 2016
[3] A. Graves, G. Wayne, and I. Danihelka
Neural Turing Machines
ArXiv, 2014